Battle Plan & War Doctrine Dec 2025
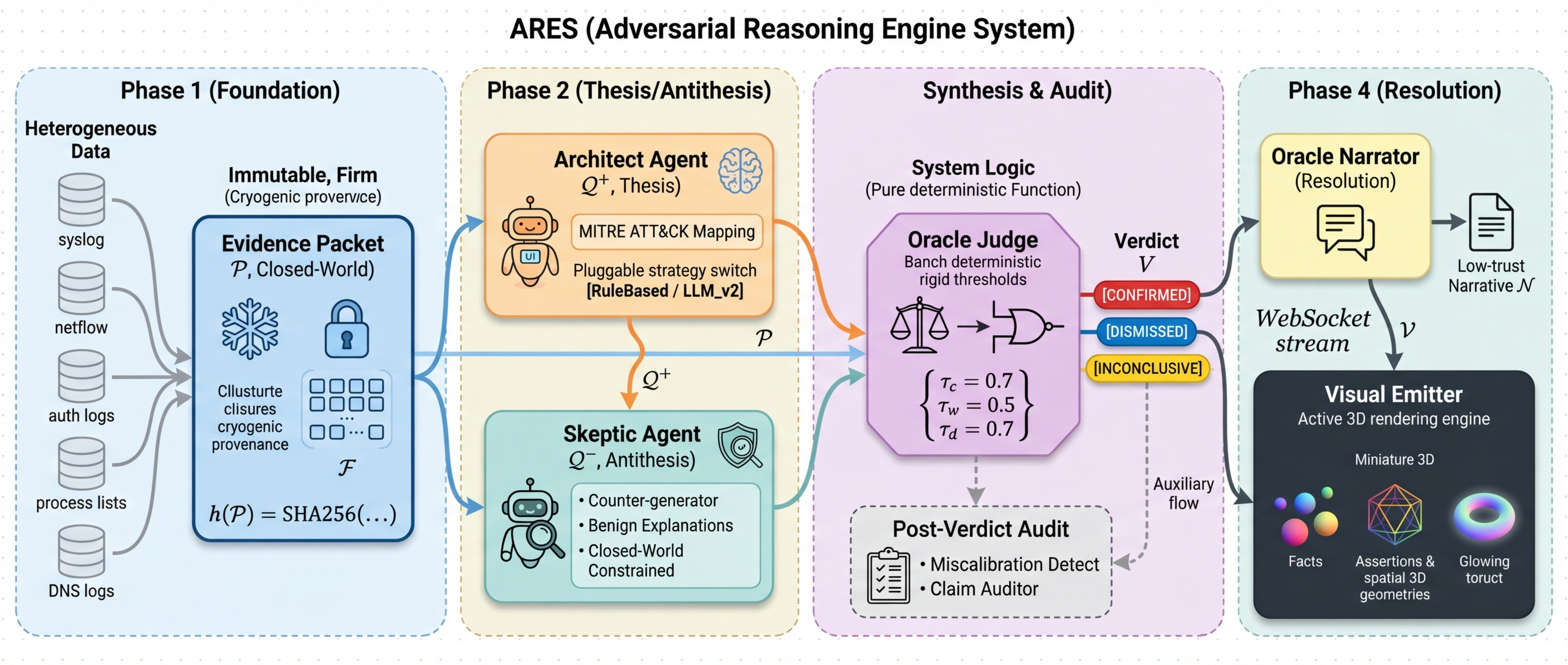
Foundational architecture documents: dialectical reasoning cycle, five attack scenarios, ethical framework aligned to NIST AI RMF. External critique identified three missing prerequisites before any code should be written: data schemas, agent I/O contracts, and a testing framework.
Session Zero — Validation Jan 2025
All documentation submitted to Claude for independent assessment. Verdict: "comprehensive, thoughtful, and architecturally sound." Key gaps identified: frozen data structures, agent I/O contracts, API specs. The build-in-public journey begins.
Sessions 001–004 — Iron Skeleton Jan 2025
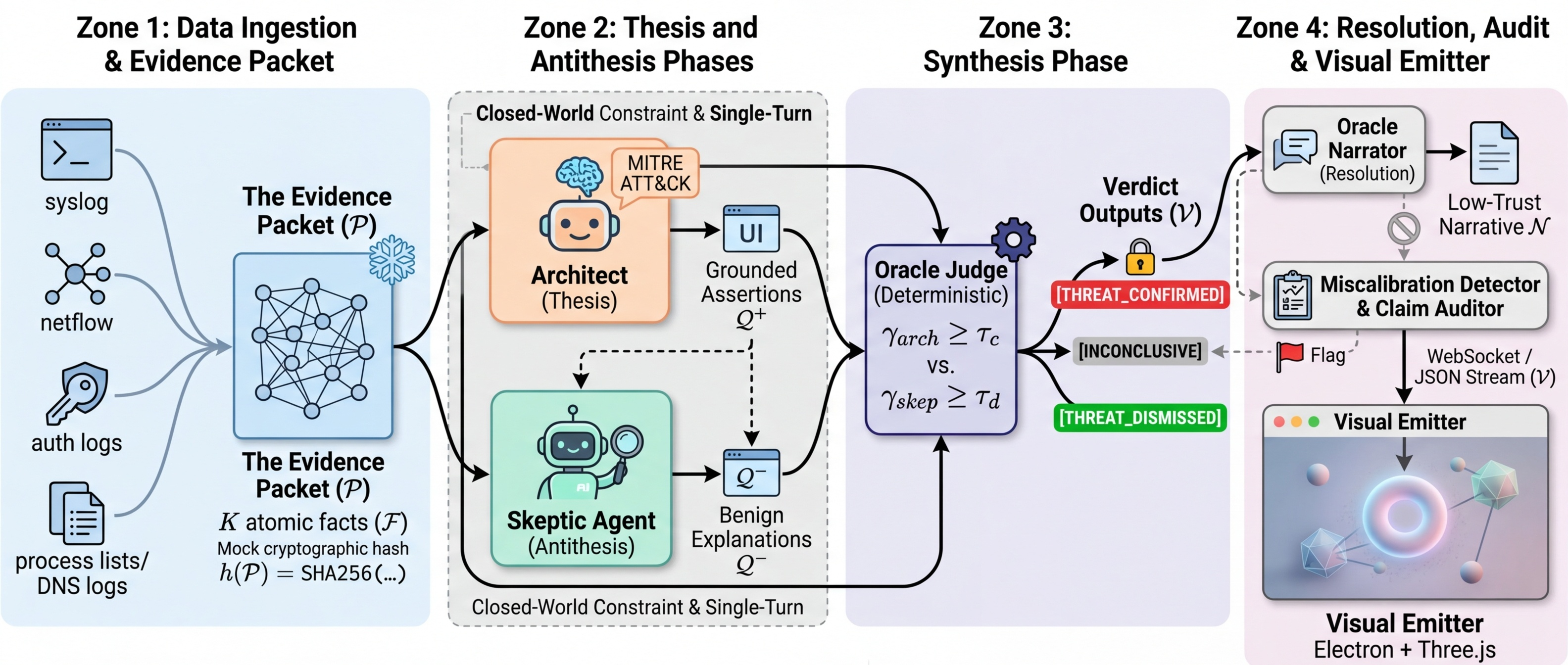
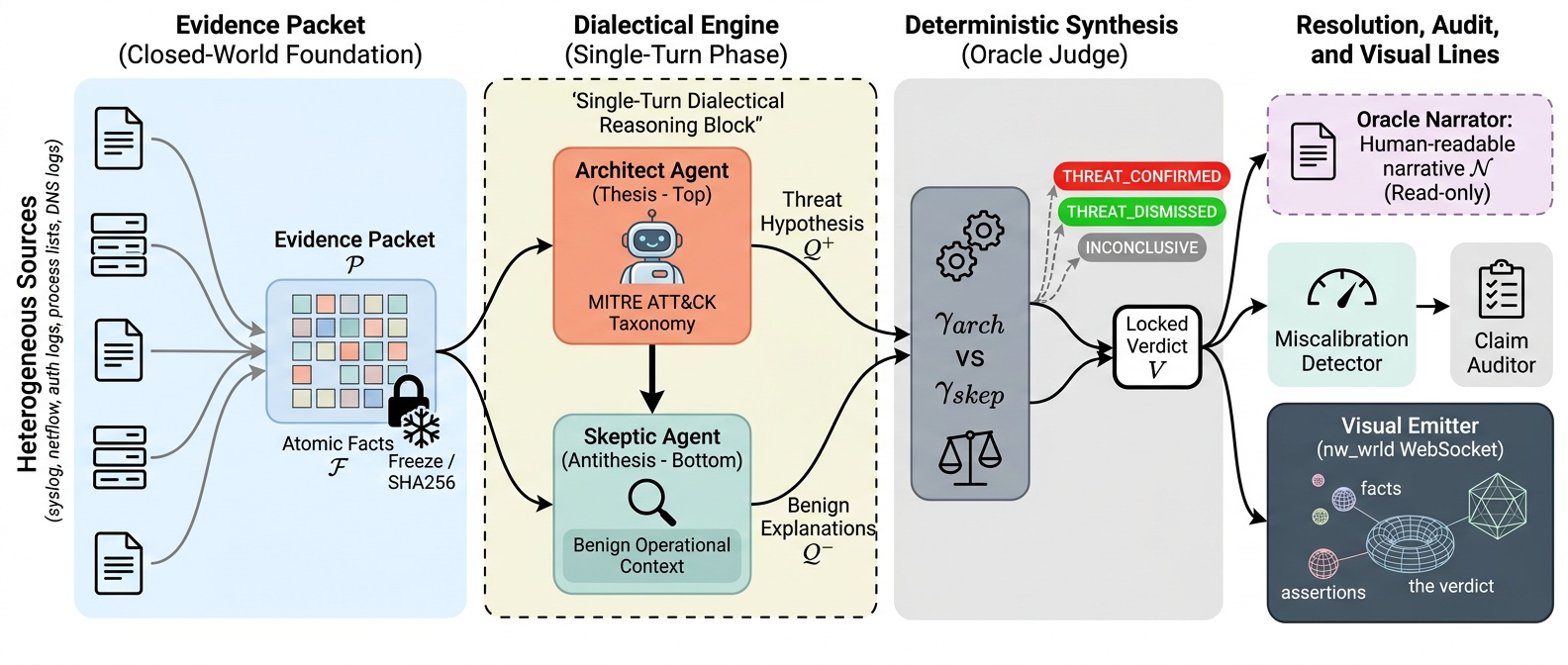
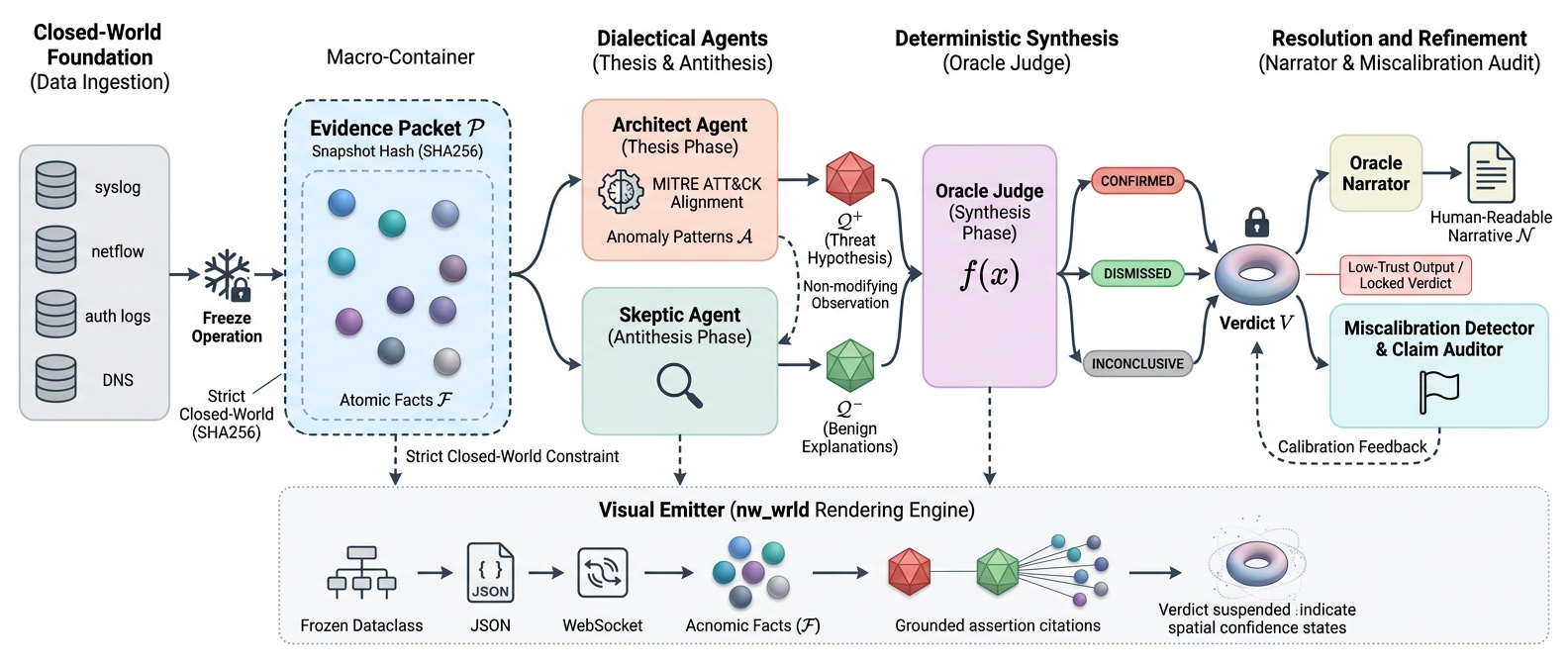
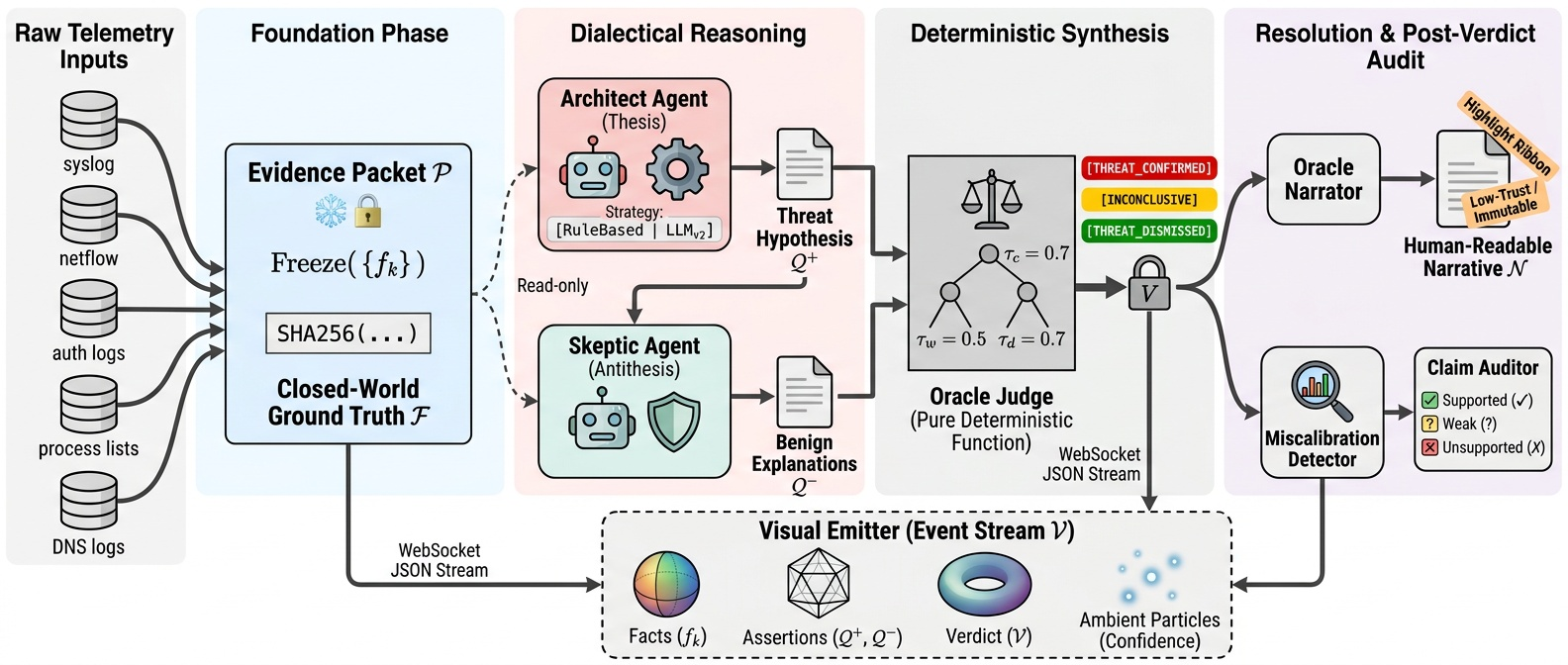
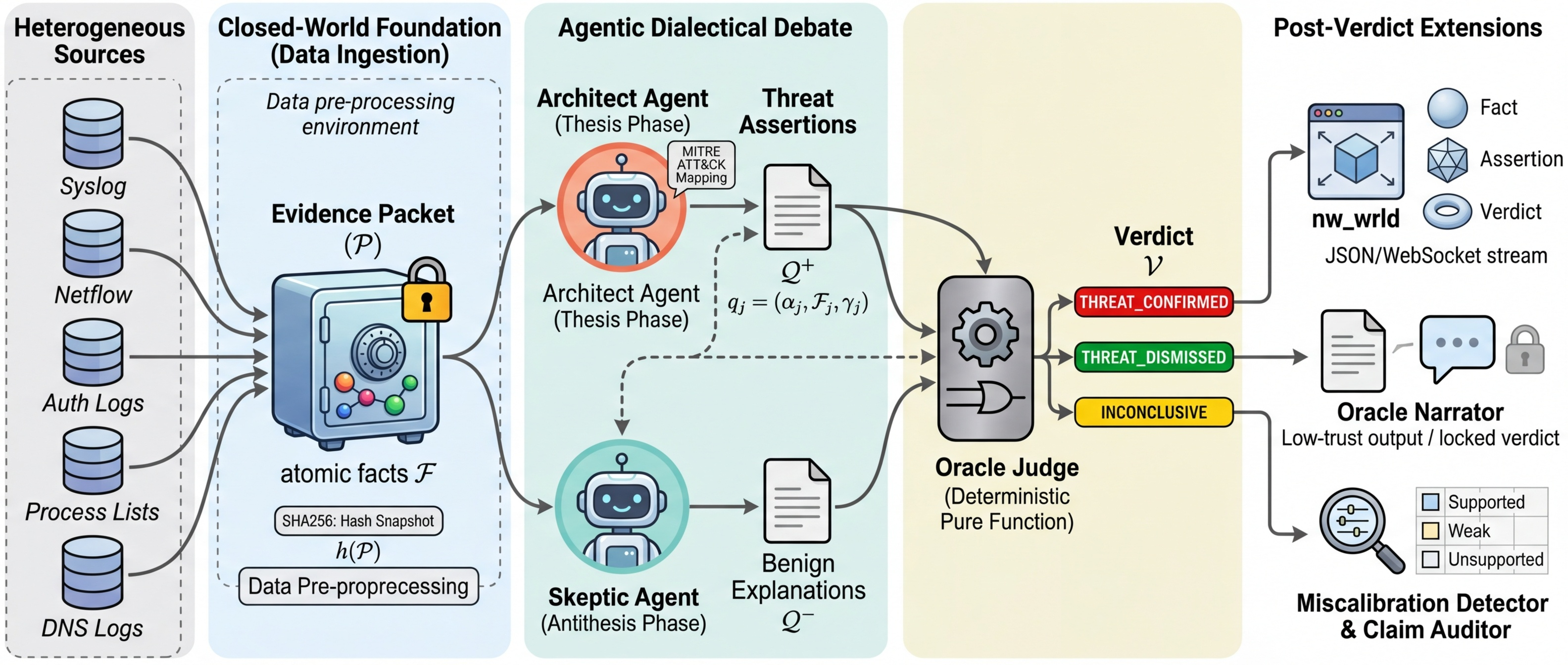
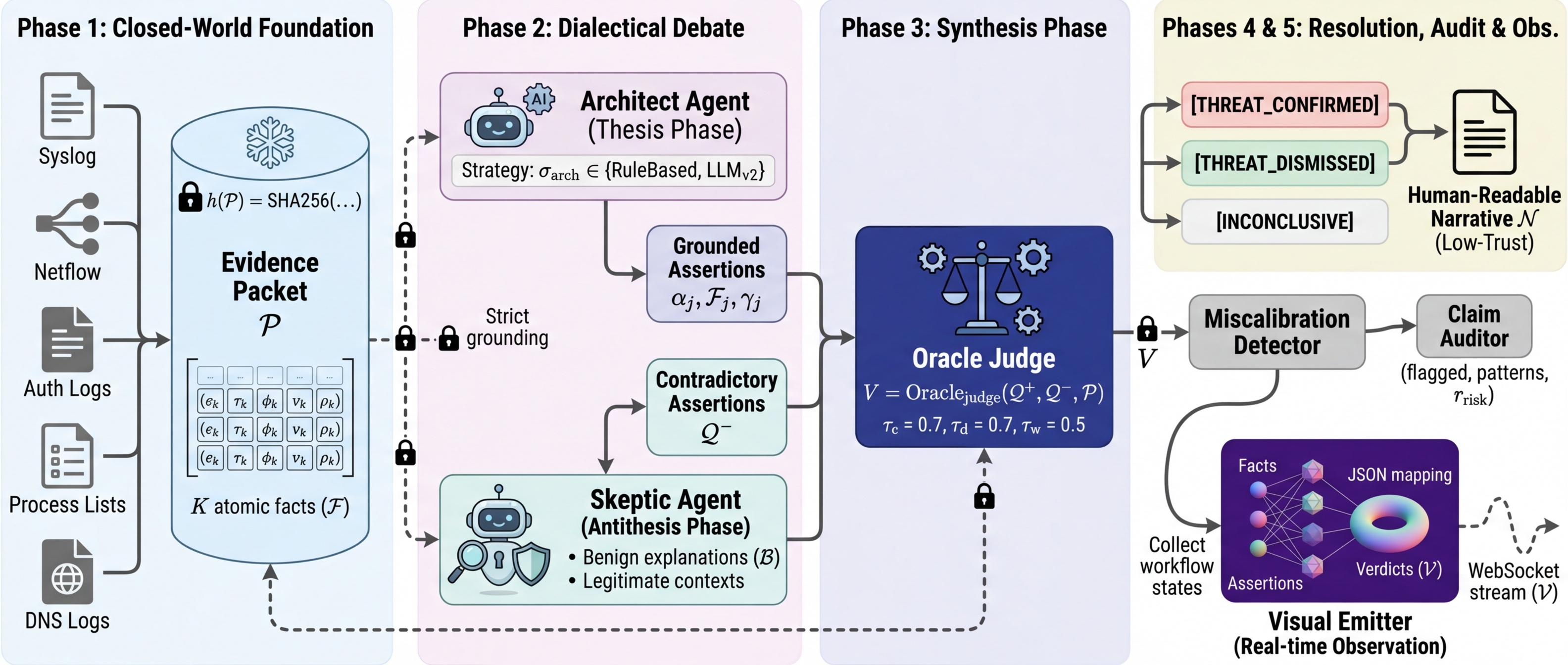
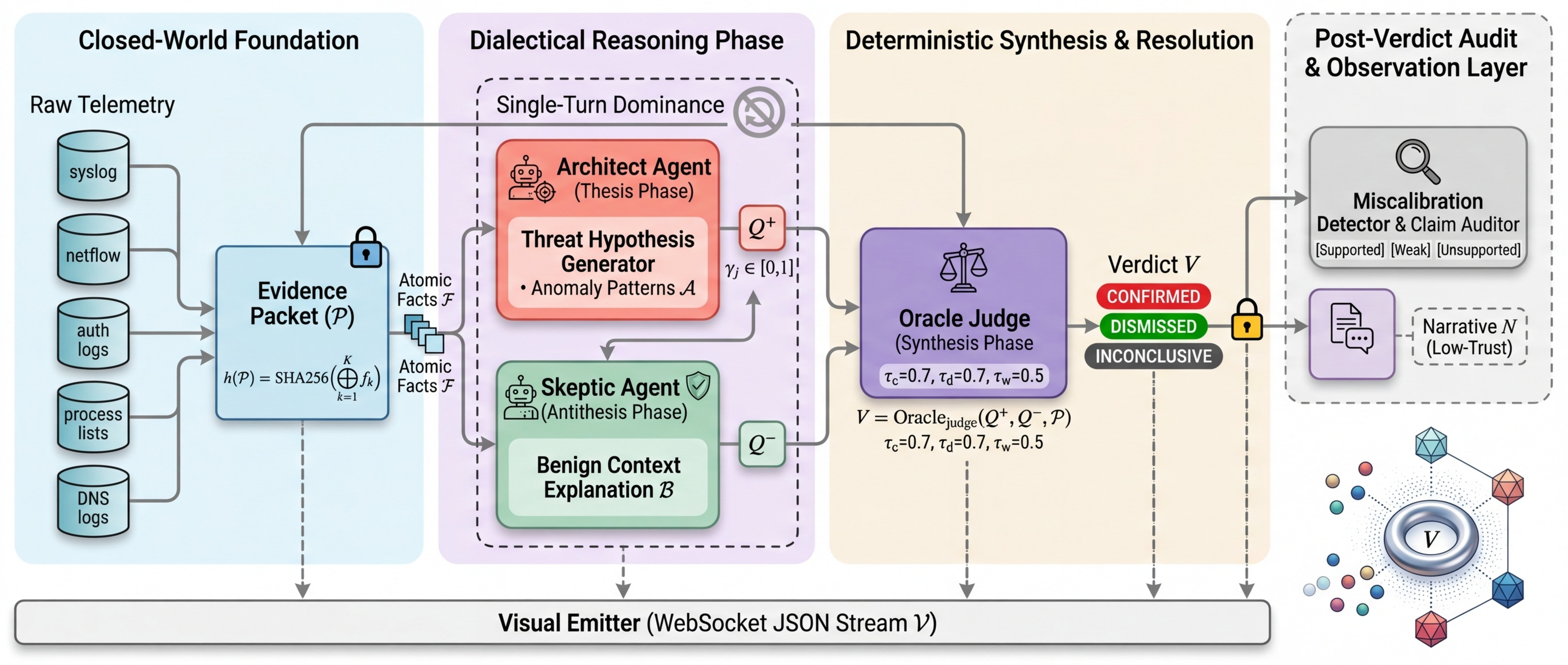
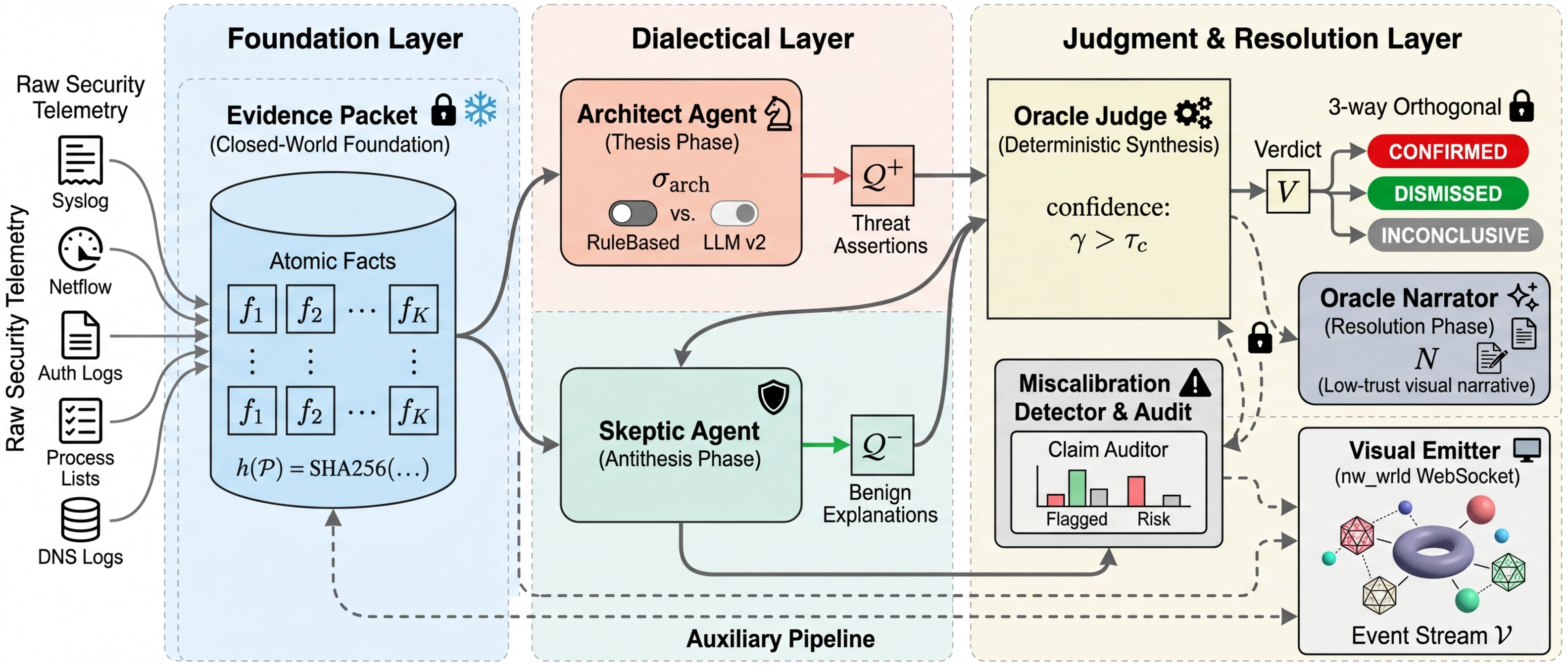
Graph Schema (6 node types, 7 edge types, 110 tests). EvidencePacket & DialecticalMessage protocol (292 tests). Agent Foundation with three hard invariants: packet binding, phase enforcement, evidence tracking. Concrete agents: Architect, Skeptic, OracleJudge, OracleNarrator. Cumulative: 570 tests passing.
Session 005 — Evidence Extractors Jan 2025
First sensor layer: Windows Security Event XML parser (Event IDs 4624, 4672, 4688). Three golden pipeline scenarios validated end-to-end from raw XML to verdict. 130 new tests. Cumulative: 700.
Sessions 006–007 — Orchestrator & Memory Feb 2026
DialecticalOrchestrator: single run_cycle(packet) call automating the full THESIS → ANTITHESIS → SYNTHESIS pipeline. Tamper-evident Memory Stream with SHA256 hash-chained audit log. Pre-session review caught a critical bug: content hash must cover the full CycleResult, not a subset. Cumulative: 861 tests.
Sessions 009–010 — LLM Integration Feb 2026
Strategy Pattern enabling rule-based and LLM-backed implementations to swap without changing agent interfaces. Closed-world validation silently filters any LLM-cited fact_id that doesn't exist in the EvidencePacket. First live LLM cycle: zero validation errors. Architect confidence 0.90 (vs 0.49 rule-based). Cost: $0.03 per cycle. Cumulative: 1,104 tests.
Sessions 011–012 — Benchmark Infrastructure Feb 2026
12-scenario gauntlet across four difficulty tiers. LLM accuracy: 91.7% on the initial 12 scenarios (up from 50% rule-based). Benchmark runner hardened with per-scenario error isolation and real cost tracking. Cumulative: 1,190 tests.
Session 013 — The Negative Result Mar 2026
Multi-turn debate experiment: accuracy dropped from 91.7% to 83.3%. Zero "good flips," 25% "bad flips." Agents re-analyzed the same packet from scratch each round; the termination condition (NO_NEW_EVIDENCE) fired correctly after round 2. SC-012 (Supply Chain) regressed due to confidence inflation without new reasoning. The multi-turn debate chapter is formally closed.
The Convergence — Multi-AI Tribunal Mar 2026
Battle Plan and Compendium submitted to GPT-5.4 Pro, Gemini 3.1 Pro, and Perplexity for independent review. Unanimous consensus: ship single-turn as the production path. The failure mode is architectural (asymmetric calibration), not fixable by prompting. Independently corroborated by ETH Zurich's "Can AI Agents Agree?" paper.
Sessions 016–017 — Multi-Source Telemetry Mar 2026
Syslog extractor (8 message types: SSH, firewall, sudo, systemd) and NetFlow extractor (8 flow types, 14 facts per record). Three independent telemetry sources feeding richer cross-source evidence to the dialectical agents. Cumulative: ~1,488 tests.
Session 022 — Escalation Gate Mar 2026
Built confidence-band escalation gate at [0.35, 0.70]. Critical finding: all 7 actual errors are MISCALIBRATED — the system is confidently wrong, not uncertainly wrong. The gate treats the wrong disease. Pivot to miscalibration detection via per-claim evidence audit. Cumulative: 1,736 tests.
Sessions 032–034 — Accuracy Push Mar 2026
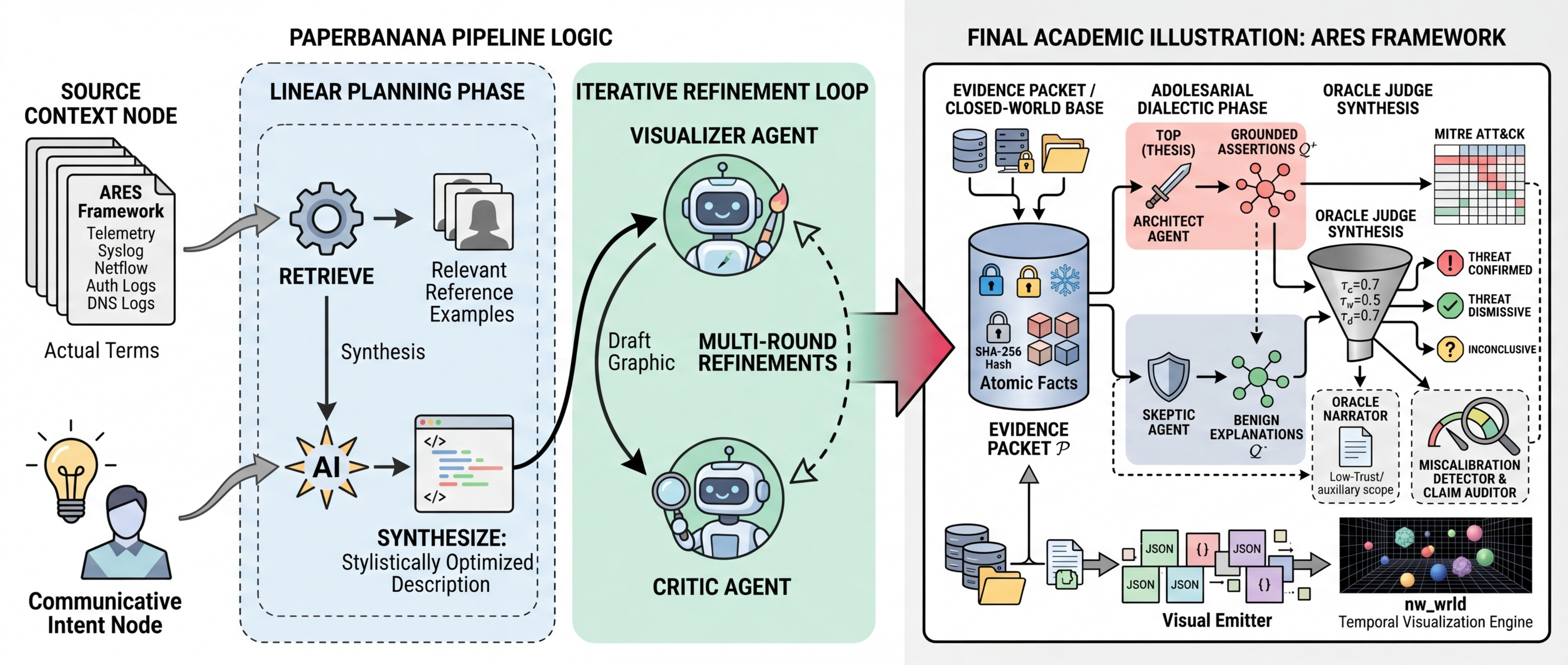
33-scenario corpus regenerated at 72.7% baseline. OracleJudgeV2 (delta-based scoring), v3 prompts (exhaustive fact citation), and threshold sweep. V4 prompt calibration confirmed the Architect hits a 0.75 confidence floor regardless of instructions — a structural property of LLM confidence quantization. Final trajectory: 50% → 91.7% (12 scenarios) → 72.7% (33 scenarios) → 81.8% (v3 prompts) → 87.9% (V2 Oracle, best config).
Sessions 029–030 — Visual Interface Mar 2026
WebSocket event emitter and 3D evidence graph. Corpus replay runner validated event sequences across all 33 scenarios deterministically. 1,948 tests passing with zero regressions.
Sessions 035–036 — ARES VISION Mar 2026
Benchmark replay pipeline consuming real LLM data. Standalone HTML/Three.js visualizer rendering evidence facts as particle clusters with citation lines and live confidence bars. Strategic pivot: nw_wrld abandoned in favor of direct WebSocket rendering for full domain control. Final test count: 1,927 passing, 65 skipped, 0 failures.
Session 041 — V2 Oracle Sweep Apr 2026
Best-config sweep across delta thresholds: delta=0.30 wins at 74.4% on 39 scenarios with zero regressions and one improvement. PentAGI integration brought a pentest baseline (33 SC + 6 PT scenarios). Cumulative: 2,350 tests.
Sessions 045–046 — Oracle Firewall + Hot-Swap Apr 2026
12 adversarial scenarios across DIRECT / FRAMING / PROPAGATION. Deterministic firewall with zero LLM calls and four violation types. Hot-swap quarantine: a fresh Architect on raw evidence when taint is detected. First live benchmark: Detection 58.3%, Verdict 41.7%, zero false positives. Surfaces Findings F07 and F08.
Sessions 047–048 — 27-Scenario Live Benchmark Apr 2026
Category B framing corpus expansion: 15 new scenarios across severity, authority, temporal, causal, and narrative strategies. Full live benchmark on Sonnet 4.6, single-turn firewall-guarded cycle, 778s wall, zero pipeline errors. Confirms Finding F07 live: deterministic firewalls catch 100% of structural injection and 0% of semantic framing.
Session 049 — Skeptic Ablation Apr 2026
Removing the Skeptic drops accuracy by 10.53 pp (0.7895 → 0.6842). Family-uneven: severity −33.33 pp, temporal −50.00 pp, narrative −25.00 pp; authority and causal hold. Authority expansion (INJ-028..030) brings family n=6 accuracy to 0.833. Finding F09: ambiguous.
Session 050 — Light Skeptic + Three-Way Benchmark Apr 2026
Headline result. A 170-line deterministic Python rule engine matches the full-LLM Skeptic on framing accuracy: Δ = 0.00 across 25 scenarios. All three live acceptance gates pass. Temporal expansion to registry_v3 (33 scenarios). Finding F11: supported.
Sessions 051–055 — Paper 2 Build & Citation Audit Apr 2026
Five 300-DPI figures, 13-section docx with 9 subsections, 18-claim numerical audit (all PASS). A hallucinated citation discovered and remediated — itself an instance of the semantic-framing failure class the paper studies. References compiled to ACM/AISec author-year format. Structural citation tests added to lock the helper contract.
Session 056 — Firewall Fail-Closed Contract Apr 2026
Producer-side and consumer-side enforcement of the firewall fail-closed invariant: passed=False ⇒ sanitized_output is not None at construction; CycleError raised at all three cycle runners on contract violation. Belt-and-suspenders defense surfaced via external multi-AI review (Cursor + Codex). Cumulative: 3,412 tests, zero regressions.
Sessions 057–060 — Tribunal V4 & Broad-Reading Measurement May 2026
Phase 7 re-entry: a new Tribunal V4 plan and a pre-registered mutator redesign (orthogonality audit + anchor test). The InfluenceLeakage broad-reading run applies 98 paired prose mutations across the 33-scenario corpus under three operators — 97/98 cycles hold their verdict. The lone INJ-001 drift fires at the Oracle layer (citation-passthrough), not a verdict collapse. Narrow-reading characterization extends to N=98 at 100% stability. Rendered as the Pinscreen.
Sessions 063–066 — ARES Prism & Paper 3 Drafting May 2026
ARES Prism Panel 2 (confidence trajectories) ships beside the Labyrinth replay. Paper 3 — Decision Determinism & Explanation Drift — is taken from skeleton brief through prose drafting.
Sessions 073–077 — Multi-Model Validation & Architect-Path Framing May 2026
Step 5 multi-model InfluenceLeakage validation across providers; narrow characterization completed; the Architect-path framing measurement isolates where steering enters. Paper 3 real figures generated.
Sessions 078–082 — Oracle Sanitizer, Paper 3 Sign-off & Scale Jun 2026
The Oracle supporting_fact_ids sanitizer (opt-in leak fix) merges and cuts over to production. Paper 3 is de-risked and signed off submission-grade. The S077 framing measurement scales to K=20 across all 17 scenarios.
Sessions 083–086 — Dual-Agent Framing & ARES-VISION Jun 2026
INJ-020 steerability is root-caused to paraphrase-triggered citation collapse, then made rigorous as a dual-agent framing measurement: the Architect collapses onto the threat fact (jaccard 0.80) while the Skeptic expands to all five (0.40) — the Oracle dismisses the threat, verdict held 1.0. That run drives the ARES-VISION suite: the Mirror and the Prism Constellation.
Session 087 — Read-Depth Robustness Frontier Jun 2026
An offline, deterministic measurement instrument for the read-depth frontier (Adaptive Corpus C; lexical and semantic evasion operators). The standalone-vs-cumulative Youden-J gap exposes the structural-detection trilemma — you cannot keep structural detection, escape its false positives, and read content all at once. Full suite: 4,265 tests passing. Fuel for Paper 4.
Paper 2 — Published Published
"Defending the Closed-World Schema Against Adversarial Framing." Five 300-DPI figures, a 13-section manuscript, an 18-claim numerical audit, references in ACM/AISec format. Carries the meta-finding footnote: a hallucinated citation the audit caught is itself an instance of the semantic-framing failure class the paper describes.
Paper 3 — In Submission Submission-grade
"Decision Determinism & Explanation Drift." Skeleton through prose drafting (Sessions 063–066), real figures (Session 073), submission de-risk and pre-flight sign-off at submission-grade (Sessions 080–081).
Paper 4 — In Progress Active
The read-depth robustness frontier and the structural-detection trilemma. Phase B shipped the offline deterministic instrument and frozen pre-registration fixtures (Session 087); the metered LLM frontier run and its verdict are the next step.